
块级别的全量增量复制技术
让我们深入了解一下 HyperBDR 是如何读取和存储数据的。
如前所述,为了实现主机级别的备份和恢复,HyperBDR 采用了块级数据同步,这意味着它可以备份主机上所有磁盘的数据。需要注意的是,这些磁盘不包括网络磁盘,例如 NFS 。
确定同步级别后,下一步就是解决数据同步问题,特别是获取全量和增量数据。
在 HyperBDR 中,数据同步主要有三种方法:
- 对于 Agent 同步,增量数据主要通过内核模块 I/O 捕获技术获取。
- 对于 VMware,我们主要利用 CBT 技术从 EXSI 捕获增量数据。
- 对于使用 Ceph 存储的 OpenStack 平台,我们利用 RBD 接口获取数据。
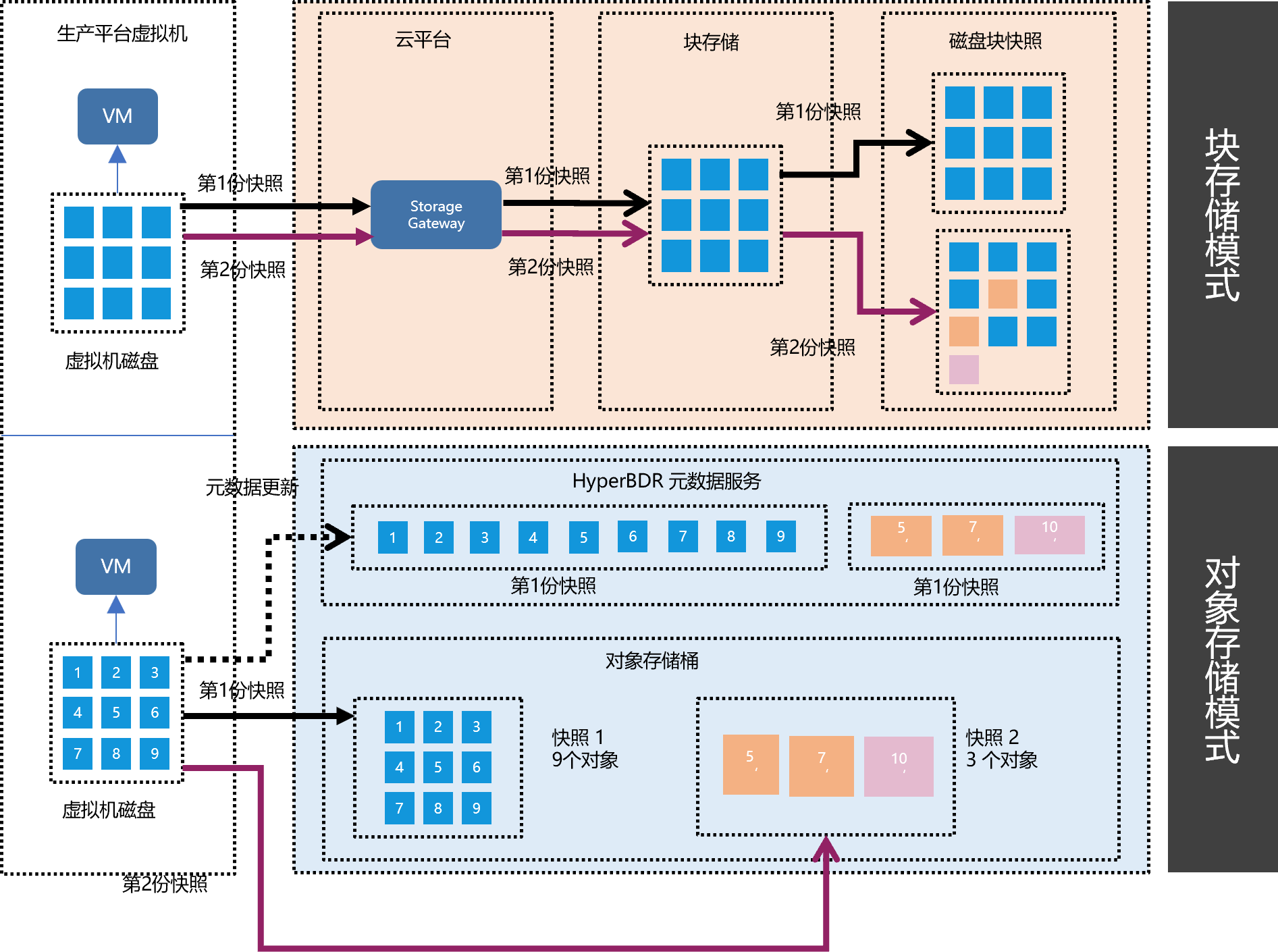
在块存储模式下,数据直接写入云平台块存储的相应位置。
如前所述,在数据同步过程中,HyperBDR 直接将从源主机捕获的数据存储在云存储中。具体来说,在块存储模式下,数据通过云同步网关直接写入云平台块存储的相应位置。最后,通过调用云平台的块存储快照接口,锁定每次同步后的数据。
这种方法的优点是,在数据同步阶段,无需在源主机和目标主机之间建立一对一的映射关系。只需要适当数量的云同步网关和相应的磁盘即可。
一个经常被问到的问题是,在数据同步期间,我需要多少个云同步网关?
首先,云同步网关的数量并不直接对应生产环境主机的数量。其次,云同步网关上挂载的磁盘数量与生产环境主机上的总磁盘数量一一对应。例如,如果源端有 10 台主机,每台主机有两个磁盘,那么在华为云上只需要一个云同步网关,因为华为云上的每台云主机可以挂载 20 个磁盘。
在对象存储模式下,数据被分成默认大小为 4MB 的区域。当检测到某个区域的更改时,该区域的数据存储在对象存储中,而相应的元数据信息则存储在 HyperBDR 中。由于对象存储本身的访问接口使用 HTTP,因此不需要额外的计算资源进行存储。